Distributed source coding
Distributed source coding (DSC) is an important problem in information theory and communication. DSC problems regard the compression of multiple correlated information sources that do not communicate with each other.[1] By modeling the correlation between multiple sources at the decoder side together with channel codes, DSC is able to shift the computational complexity from encoder side to decoder side, therefore provide appropriate frameworks for applications with complexity-constrained sender, such as sensor networks and video/multimedia compression (see distributed video coding[2]). One of the main properties of distributed source coding is that the computational burden in encoders is shifted to the joint decoder.
History
In 1973, David Slepian and Jack Keil Wolf proposed the information theoretical lossless compression bound on distributed compression of two statistically dependent i.i.d. sources X and Y.[3] After that, this bound was extended to cases with more than two sources by Thomas M. Cover in 1975,[4] while the theoretical results on lossy compression case are presented by Aaron D. Wyner and Jacob Ziv in 1976.[5]
Although the theorems on DSC were proposed on 1970s, it was after about 30 years that attempts were started for practical techniques, based on the idea that DSC is closely related to channel coding proposed in 1974 by Aaron D. Wyner.[6] The asymmetric DSC problem was addressed by S. S. Pradhan and K. Ramchandran in 1999, which focused on statistically dependent binary and Guassian sources and used scalar and trellis coset constructions to solve the problem.[7] They further extended the work into symmetric DSC case lately.[8]
Syndrome decoding technology was first used in distributed source coding by the DISCUS system of SS Pradhan and K Ramachandran (Distributed Source Coding Using Syndromes).[7] They compress binary block data from one source into syndromes and transmit data from the other source uncompressed as side information. This kind of DSC scheme achieves asymmetric compression rates per sources and results in asymmetric DSC. This asymmetric DSC scheme can be easily extended to the case of more than two correlated information sources. There are also some DSC schemes that use parity bits rather than syndrome bits.
The correlation between two sources in DSC has been modelled as a virtual channel which is usually referred as a binary symmetric channel.[9][10]
Starting from DISCUS, DSC has attracted significant research activity and more sophisticated channel coding techniques have been adopted into DSC frameworks, such as Turbo Code, LDPC Code, and so on.
Similar to previous lossless coding framework based on Slepian-Wolf theorem, efforts have been taken on lossy cases based on Wyner-Ziv theorem. Theoretical result on quantizer designs was provided by R. Zamir and S. Shamai,[11] while different frameworks have been proposed based on this result, including nested lattice quantizer and trellis-coded quantizer.
Moreover, DSC has been used in video compression for applications which require low complexity video encoding, such as sensor networks, multiview video camcorders, and so on.[12]
With deterministic and probabilistic discussions of correlation model of two correlated information sources, DSC schemes with more general compressed rates have been developed.[13][14][15] In these non-asymmetric schemes, both of two correlated sources are compressed.
Under a certain deterministic assumption of correlation between information sources, a DSC framework in which any number of information sources can be compressed in a distributed way has been demonstrated by X. Cao and M. Kuijper.[16] This method performs non-asymmetric compression with flexible rates for each source, achieving the same overall compression rate as repeatedly applying asymmetric DSC for more than two sources.
Theoretical bounds
The information theoretical lossless compression bound on DSC (the Slepian-Wolf bound) was first purposed by David Slepian and Jack Keil Wolf in terms of entropies of correlated information sources in 1973.[3] They also showed that two isolated sources can compress data as efficiently as though they communicating with each other. This bound has been extended to the case of more than two correlated sources by Thomas M. Cover in 1975.[4]
Similar results were obtained in 1976 by Aaron D. Wyner and Jacob Ziv with regard to lossy coding of joint Gaussian sources.[5]
Slepian–Wolf bound
Distributed Coding is the coding of two or more dependent sources with separate encoders and joint decoder. Given two statistically dependent i.i.d. finite-alphabet random sequences X and Y, Slepian-Wolf theorem includes theoretical bound for the lossless coding rate for distributed coding of the two sources as below[3]:
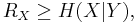
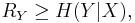
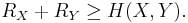
If both encoder and decoder of the two sources are independent, the lowest rate we can achieve for lossless compression is 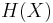 and
and 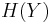 for
for 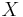 and
and 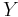 respectively, where and are the entropies of and . However, with joint decoding, if vanishing error probability for long sequences is accepted, Slepian-Wolf theorem shows that much better compression rate can be achieved. As long as the total rate of and is larger than their joint entropy
respectively, where and are the entropies of and . However, with joint decoding, if vanishing error probability for long sequences is accepted, Slepian-Wolf theorem shows that much better compression rate can be achieved. As long as the total rate of and is larger than their joint entropy 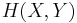 and none of the sources is encoded with rate larger than its entropy, distributed coding can achieve arbitrarily small error probability for long sequences.
and none of the sources is encoded with rate larger than its entropy, distributed coding can achieve arbitrarily small error probability for long sequences.
A special case of distributed coding is compression with decoder side information, where source is available at the decoder side but not accessible at the encoder side. That can be treated as the condition that 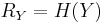 has already been used to encode , while we intend to use
has already been used to encode , while we intend to use 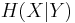 to encode . The whole system is operating in an asymmetric way (compression rate for the two sources are asymmetric).
to encode . The whole system is operating in an asymmetric way (compression rate for the two sources are asymmetric).
Wyner–Ziv bound
Shortly after Slepian-Wolf theorem on lossless distributed compression was published, the extension to lossy compression with decoder side information was proposed as Wyner-Ziv theorem.[5] Similarly to lossless case, two statistically dependent i.i.d. sources and are given, where is available at the decoder side but not accessible at the encoder side. Instead of lossless compression in Slepian-Wolf theorem, Wyner-Ziv theorem looked into the lossy compression case.
Wyner-Ziv theorem presents the achievable lower bound for the bit rate of at given distortion 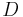 . It was found that for Guassian memoryless sources and mean-squared error distortion, the lower bound for the bit rate of remain the same no matter whether side information is available at the encoder or not.
. It was found that for Guassian memoryless sources and mean-squared error distortion, the lower bound for the bit rate of remain the same no matter whether side information is available at the encoder or not.
Virtual channel
Deterministic model
Probabilistic model
Asymmetric DSC vs. symmetric DSC
Asymmetric DSC means that, different bitrates are used in coding the input sources, while same bitrate is used in symmetric DSC. Taking a DSC design with two sources for example, in this example and are two discrete, memoryless, uniformly distributed sources which generate set of variables 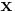 and
and 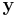 of length 7 bits and the Hamming distance between and is at most one. The Slepian-Wolf bound for them is:
of length 7 bits and the Hamming distance between and is at most one. The Slepian-Wolf bound for them is:
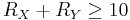
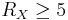
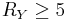
This means, the theoretical bound is 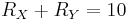 and symmetric DSC means 5 bits for each source. Other pairs with are asymmetric cases with different bit rate distributions between and , where
and symmetric DSC means 5 bits for each source. Other pairs with are asymmetric cases with different bit rate distributions between and , where 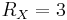 ,
, 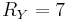 and
and 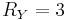 ,
, 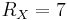 represent two extreme cases called decoding with side information.
represent two extreme cases called decoding with side information.
Practical distributed source coding
Slepian-Wolf coding – lossless distributed coding
It was understood that Slepian–Wolf coding is closely related to channel coding in 1974,[6] and after about 30 years, practical DSC started to be implemented by different channel codes. The motivation behind the use of channel codes is from two sources case, the correlation between input sources can be modeled as a virtual channel which has input as source and output as source . The DISCUS system proposed by S. S. Pradhan and K. Ramchandran in 1999 implemented DSC with syndrome decoding, which worked for asymmetric case and was further extended to symmetric case.[7][8]
The basic framework of syndrome based DSC is that, for each source, its input space is partitioned into several cosets according to the particular channel coding method used. Every input of each source gets an output indicating which coset the input belongs to, and the joint decoder can decode all inputs by received coset indices and dependence between sources. The design of channel codes should consider the correlation between input sources.
A group of codes can be used to generate coset partitions,[17] such as trellis codes and lattice codes. Pradhan and Ramchandran designed rules for construction of sub-codes for each source, and presented result of trellis-based coset constructions in DSC, which is based on convolution code and set-partitioning rules as in Trellis modulation, as well as lattice code based DSC.[7][8] After this, embedded trellis code was proposed for asymmetric coding as an improvement over their results.[18]
After DISCUS system was proposed, more sophisticated channel codes have been adapted to the DSC system, such as Turbo Code, LDPC Code and Iterative Channel Code. The encoders of these codes are usually simple and easy to implemente, while the decoders have much higher computational complexity and are able to get good performance by utilizing source statistics. With sophisticated channel codes which have performance approaching the capacity of the correlation channel, corresponding DSC system can approach the Slepian–Wolf bound.
Although most research focused on DSC with two dependent sources, Slepian–Wolf coding has been extended to more than two input sources case, and sub-codes generation methods from one channel code was proposed by V. Stankovic, A. D. Liveris, etc. given particular correlation models.[19]
General theorem of Slepian–Wolf coding with syndromes for two sources
Theorem: Any pair of correlated uniformly distributed sources, 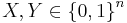 , with
, with 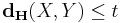 , can be compressed separately at a rate pair
, can be compressed separately at a rate pair 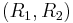 such that
such that 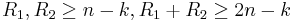 , where
, where 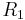 and
and 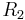 are integers, and
are integers, and 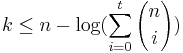 . This can be achieved using an
. This can be achieved using an 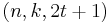 binary linear code.
binary linear code.
Proof: The Hamming bound for an binary linear code is , and we have Hamming code achieving this bound, therefore we have such an binary linear code 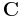 with
with  generator matrix
generator matrix 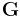 . Next we will show how to construct syndrome encoding based on this linear code.
. Next we will show how to construct syndrome encoding based on this linear code.
Let 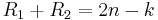 and
and 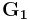 be formed by taking first
be formed by taking first 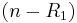 rows from , while
rows from , while 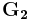 is formed using the remaining
is formed using the remaining 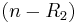 rows of .
rows of . 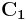 and
and 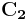 are the subcodes of the Hamming code generated by and respectively, with
are the subcodes of the Hamming code generated by and respectively, with 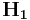 and
and 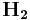 as their parity check matrices.
as their parity check matrices.
For a pair of input 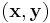 , the encoder is given by
, the encoder is given by 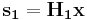 and
and 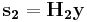 . That means, we can represent and as
. That means, we can represent and as 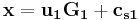 ,
, 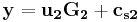 , where
, where 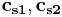 are the representatives of the cosets of
are the representatives of the cosets of 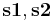 with regard to
with regard to 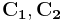 respectively. Since we have
respectively. Since we have 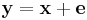 with
with 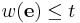 . We can get
. We can get 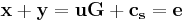 , where
, where ![\mathbf{u=\left[ u_1, u_2\right] }](/2012-wikipedia_en_all_nopic_01_2012/I/eb7c0ec900557344128aa840f4ffd67b.png) ,
, 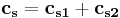 .
.
Suppose there are two different input pairs with the same syndromes, that means there are two different strings 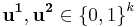 , such that
, such that 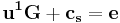 and
and 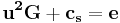 . Thus we will have
. Thus we will have 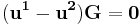 . Because minimum Hamming weight of the code is
. Because minimum Hamming weight of the code is 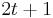 , the distance between
, the distance between 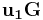 and
and 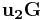 is
is 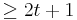 . On the other hand, according to together with and , we will have
. On the other hand, according to together with and , we will have 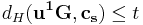 and
and 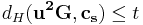 , which contradict with
, which contradict with 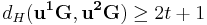 . Therefore, we cannot have more than one input pairs with the same syndromes.
. Therefore, we cannot have more than one input pairs with the same syndromes.
Therefore, we can successfully compress the two dependent sources with constructed subcodes from an binary linear code, with rate pair such that , where and are integers, and . Log indicates Log2.
Slepian–Wolf coding example
Take the same example as in the previous Asymmetric DSC vs. Symmetric DSC part, this part presents the corresponding DSC schemes with coset codes and syndromes including asymmetric case and symmetric case. The Slepian–Wolf bound for DSC design is shown in the previous part.
Asymmetric case (, )
In this case, the length of an input variable from source is 7 bits, therefore it can be sent lossless with 7 bits independent of any other bits. Based on the knowledge that and have Hamming distance at most one, for input from source , since the receiver already has , the only possible are those with at most 1 distance from . If we model the correlation between two sources as a virtual channel, which has input and output , as long as we get , all we need to successfully "decode" is "parity bits" with particular error correction ability, taking the difference between and as channel error. We can also model the problem with cosets partition. That is, we want to find a channel code, which is able to partition the space of input into several cosets, where each coset has a unique syndrome associated with it. With a given coset and , there is only one that is possible to be the input given the correlation between two sources.
In this example, we can use the 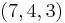 binary Hamming Code , with parity check matrix
binary Hamming Code , with parity check matrix 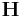 . For an input from source , only the syndrome given by
. For an input from source , only the syndrome given by 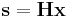 is transmitted, which is 3 bits. With received and
is transmitted, which is 3 bits. With received and 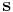 , suppose there are two inputs
, suppose there are two inputs 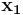 and
and 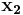 with same syndrome . That means
with same syndrome . That means 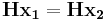 , which is
, which is 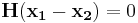 . Since the minimum Hamming weight of Hamming Code is 3,
. Since the minimum Hamming weight of Hamming Code is 3, 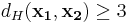 . Therefore the input can be recovered since
. Therefore the input can be recovered since 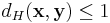 .
.
Similarly, the bits distribution with , can be achieved by reversing the roles of and .
Symmetric case
In symmetric case, what we want is equal bitrate for the two sources: 5 bits each with separate encoder and joint decoder. We still use linear codes for this system, as we used for asymmetric case. The basic idea is similar, but in this case, we need to do coset partition for both sources, while for a pair of received syndromes (corresponds to one coset), only one pair of input variables are possible given the correlation between two sources.
Suppose we have a pair of linear code and and an encoder-decoder pair based on linear codes which can achieve symmetric coding. The encoder output is given by: and . If there exists two pair of valid inputs 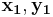 and
and 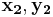 generating the same syndromes, i.e.
generating the same syndromes, i.e. 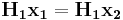 and
and 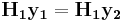 , we can get following(
, we can get following(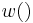 represents Hamming weight):
represents Hamming weight):
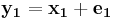 , where
, where 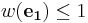
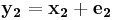 , where
, where 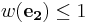
Thus: 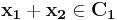
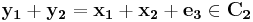
where 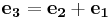 and
and 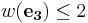 . That means, as long as we have the minimum distance between the two codes larger than
. That means, as long as we have the minimum distance between the two codes larger than 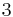 , we can achieve error-free decoding.
, we can achieve error-free decoding.
The two codes and can be constructed as subcodes of the Hamming code and thus has minimum distance of . Given the generator matrix of the original Hamming code, the generator matrix for is constructed by taking any two rows from , and is constructed by the remaining two rows of . The corresponding 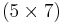 parity-check matrix for each sub-code can be generated according to the generator matrix and used to generate syndrome bits.
parity-check matrix for each sub-code can be generated according to the generator matrix and used to generate syndrome bits.
Wyner–Ziv coding – lossy distributed coding
In general, a Wyner–Ziv coding scheme is obtained by adding a quantizer and a de-quantizer to the Slepian–Wolf coding scheme. Therefore, a Wyner–Ziv coder design could focus on the quantizer and corresponding reconstruction method design. Several quantizer designs have been proposed, such as a nested lattice quantizer,[20] trellis code quantizer[21] and Lloyd quantization method.[22]
Large scale distributed quantization
Unfortunately, the above approaches do not scale (in design or operational complexity requirements) to sensor networks of large sizes, a scenario where distributed compression is most helpful. If there are N sources transmitting at R bits each (with some distributed coding scheme), the number of possible reconstructions scales 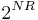 . Even for moderate values of N and R (say N=10, R = 2), prior design schemes become impractical. Recently, an approach,[23] using ideas borrowed from Fusion Coding of Correlated Sources , has been proposed where design and operational complexity are traded against decoder performance. This has allowed distributed quantizer design for network sizes reaching 60 sources, with substantial gains over traditional approaches.
. Even for moderate values of N and R (say N=10, R = 2), prior design schemes become impractical. Recently, an approach,[23] using ideas borrowed from Fusion Coding of Correlated Sources , has been proposed where design and operational complexity are traded against decoder performance. This has allowed distributed quantizer design for network sizes reaching 60 sources, with substantial gains over traditional approaches.
The central idea is the presence of a bit-subset selector which maintains a certain subset of the received (NR bits, in the above example) bits for each source. Let 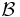 be the set of all subsets of the NR bits i.e.
be the set of all subsets of the NR bits i.e.
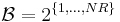
Then, we define the bit-subset selector mapping to be
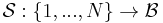
Note that each choice of the bit-subset selector imposes a storage requirement (C) that is exponential in the cardinality of the set of chosen bits.
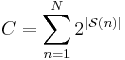
This allows a judicious choice of bits that minimize the distortion, given the constraints on decoder storage. Additional limitations on the set of allowable subsets are still needed. The effective cost function that needs to be minimized is a weighted sum of distortion and decoder storage
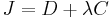
The system design is performed by iteratively (and incrementally) optimizing the encoders, decoder and bit-subset selector till convergence.
Non-asymmetric DSC
Non-asymmetric DSC for more than two sources
The syndrome approach can still be used for more than two sources. Let us consider 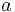 binary sources of length-
binary sources of length-
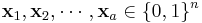 . Let
. Let 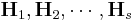 be the corresponding coding matrices of sizes
be the corresponding coding matrices of sizes 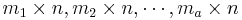 . Then the input binary sources are compressed into
. Then the input binary sources are compressed into 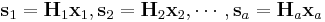 of total
of total 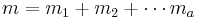 bits. Apparently, two source tuples cannot be recovered at the same time if they share the same syndrome. In other words, if all source tuples of interest have different syndromes, then one can recover them losslessly.
bits. Apparently, two source tuples cannot be recovered at the same time if they share the same syndrome. In other words, if all source tuples of interest have different syndromes, then one can recover them losslessly.
General theoretical result does not seem to exist. However, for a restricted kind of source so-called Hamming source [24] that only has at most one source different from the rest and at most one bit location not all identical, practical lossless DSC is shown to exist in some cases. For the case when there are more than two sources, the number of source tuple in a Hamming source is 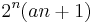 . Therefore, a packing bound that
. Therefore, a packing bound that 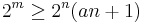 obviously has to satisfy. When the packing bound is satisfied with equality, we may call such code to be perfect (an analogous of perfect code in error correcting code).[24]
obviously has to satisfy. When the packing bound is satisfied with equality, we may call such code to be perfect (an analogous of perfect code in error correcting code).[24]
A simplest set of 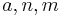 to satisfy the packing bound with equality is
to satisfy the packing bound with equality is 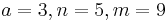 . However, it turns out that such syndrome code does not exist.[25] The simplest (perfect) syndrome code with more than two sources have
. However, it turns out that such syndrome code does not exist.[25] The simplest (perfect) syndrome code with more than two sources have 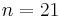 and
and 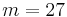 . Let
. Let



![\mathbf{G} = [ \mathbf{0} | \mathbf{I}_9]](/2012-wikipedia_en_all_nopic_01_2012/I/1d75ef8008e4f2a5c2d8f99cdadce26b.png) , and
, and 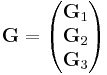 such that
such that 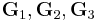 are any partition of .
are any partition of .
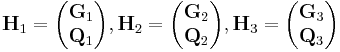 can compress a Hamming source (i.e., sources that have no more than one bit different will all have different syndromes).[24] For example, for the symmetric case, a possible set of coding matrices are
can compress a Hamming source (i.e., sources that have no more than one bit different will all have different syndromes).[24] For example, for the symmetric case, a possible set of coding matrices are 


See also
References
- ^ "Distributed source coding for sensor networks" by Z. Xiong, A.D. Liveris, and S. Cheng
- ^ "Distributed video coding in wireless sensor networks" by Puri, R. Majumdar, A. Ishwar, P. Ramchandran, K.
- ^ a b c "Noiseless coding of correlated information sources" by D. Slepian and J. Wolf
- ^ a b "A proof of the data compression theorem of Slepian and Wolf for ergodic sources" by T. Cover
- ^ a b c "The rate-distortion function for source coding with side information at the decoder" by A. Wyner and J. Ziv
- ^ a b "Recent results in Shannon theory" by A. D. Wyner
- ^ a b c d "Distributed source coding using syndromes (DISCUS): design and construction" by S. S. Pradhan and K. Ramchandran
- ^ a b c "Distributed source coding: symmetric rates and applications to sensor networks" by S. S. Pradhan and K. Ramchandran
- ^ "Distributed code constructions for the entire Slepian-Wolf rate region for arbitrarily correlated sources" by Schonberg, D. Ramchandran, K. Pradhan, S.S.
- ^ "Generalized coset codes for distributed binning" by Pradhan, S.S. Ramchandran, K.
- ^ "Nested linear/lattice codes for Wyner-Ziv encoding" by R. Zamir and S. Shamai
- ^ "Distributed Video Coding" by B. Girod, etc.
- ^ "On code design for the Slepian-Wolf problem and lossless multiterminal networks" by Stankovic, V. Liveris, A.D. Zixiang Xiong Georghiades, C.N.
- ^ "A general and optimal framework to achieve the entire rate region for Slepian-Wolf coding" by P. Tan and J. Li
- ^ "Distributed source coding using short to moderate length rate-compatible LDPC codes: the entire Slepian-Wolf rate region" by Sartipi, M. Fekri, F.
- ^ "A distributed source coding framework for multiple sources" by Xiaomin Cao and Kuijper, M.
- ^ "Coset codes. I. Introduction and geometrical classification" by G. D. Forney
- ^ "Design of trellis codes for source coding with side information at the decoder" by X. Wang and M. Orchard
- ^ "Design of Slepian–Wolf codes by channel code partitioning" by V. Stankovic, A. D. Liveris, Z. Xiong and C. N. Georghiades
- ^ "Nested quantization and Slepian–Wolf coding: a Wyner–Ziv coding paradigm for i.i.d. sources" by Z. Xiong, A. D. Liveris, S. Cheng and Z. Liu
- ^ "Wyner–Ziv coding based on TCQ and LDPC codes" by Y. Yang, S. Cheng, Z. Xiong and W. Zhao
- ^ "Design of optimal quantizers for distributed source coding" by D. Rebollo-Monedero, R. Zhang and B. Girod
- ^ "Towards large scale distributed source coding" by S. Ramaswamy, K. Viswanatha, A. Saxena and K. Rose
- ^ a b c "Hamming Codes for Multiple Sources" by R. Ma and S. Cheng
- ^ "The Non-existence of Length-5 Slepian-Wolf Codes of Three Sources" by S. Cheng and R. Ma